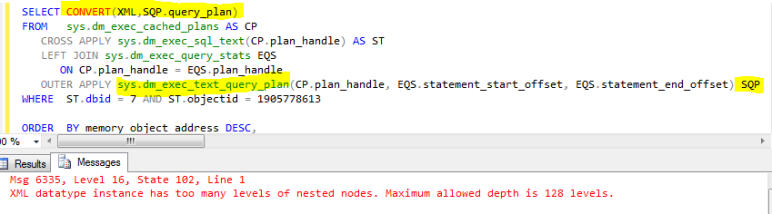
SQL Server has a number of aggregate functions including MAX, COUNT and AVG, but if you want to calculate MEDIAN you will be rolling your own, probably with a little help from Google. If your data is appropriately indexed and performance is critical then Paul White has your back: the OFFSET-FETCH method from 2012 and a dynamic cursor method for earlier versions, both calculated singly, and per group. It’s hard to imagine a faster solution as those provided pretty much jump direct to the median values.
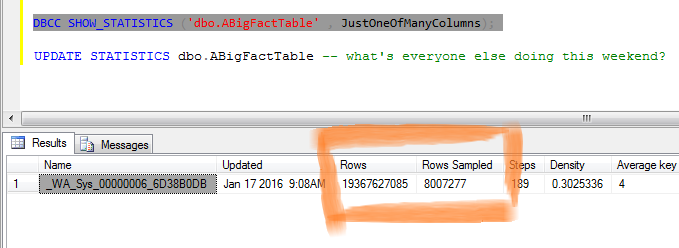
For data without a supporting index it gets a lot more interesting as established methods are quite memory and time-consuming: they all involve sorting the data. Dwain Camps seems to have developed the leading approach and applied it per group. This built on Aaron Bertrand’s work documenting and running performance tests across a single dataset.
I have a few ideas to present that will massively strip back the amount of sorting required to calculate medians without an index, resulting in huge performance gains. Unfortunately these solutions are quite “elaborate”, but I’ve managed to avoid unsupported features, query hints and trace flags (for a change).
Continue reading